Taxonomieën en ontologieën voor cybersecurity
Expertblogs
Nieuwkomers in het vakgebied maar ook experts met jarenlange ervaring worstelen soms om het overzicht te houden over terminologie en classificaties die te maken hebben met events, dreigingen, kwetsbaarheden, ATP's, enzovoorts. Met dit expertblog wil ik algemene kennis over taxonomieën en ontologieën delen. Dit is belangrijk omdat ze kunnen bijdragen aan beter begrip en duiding van complexe cybersecurityvraagstukken. Ook draagt het bij aan betere samenwerking en informatiedeling tussen verschillende organisaties en mensen.
De ontwikkeling van cybersecurity-classificaties
Cybersecurity-classificaties worden voor uiteenlopende doeleinden ontwikkeld door bijvoorbeeld wetenschappers, overheden, commerciële cybersecurity bedrijven of door kennisorganisaties. De laatste 50 jaar zijn er vele gepubliceerd. Op basis van mijn verzameling van 215 publicaties over cybersecurity-classificaties van de laatste 50 jaar (ja, ik heb curieuze hobby’s en verzamelingen...) zie ik dat al in de jaren 70 van de vorige eeuw publicaties verschenen waarin kwetsbaarheden en bedreigingen voor computersecurity werden geclassificeerd. Deze classificaties waren voornamelijk bedoeld als ontwerpeisen voor systeemontwikkeling vanuit het inzicht dat het beter was om security tijdens het ontwerp aan te pakken in plaats van achteraf. Denk je nu ook: he, dat klinkt als security-by-design? Jazeker, dat proberen we dus al ruim 50 jaar tussen de oren te krijgen.
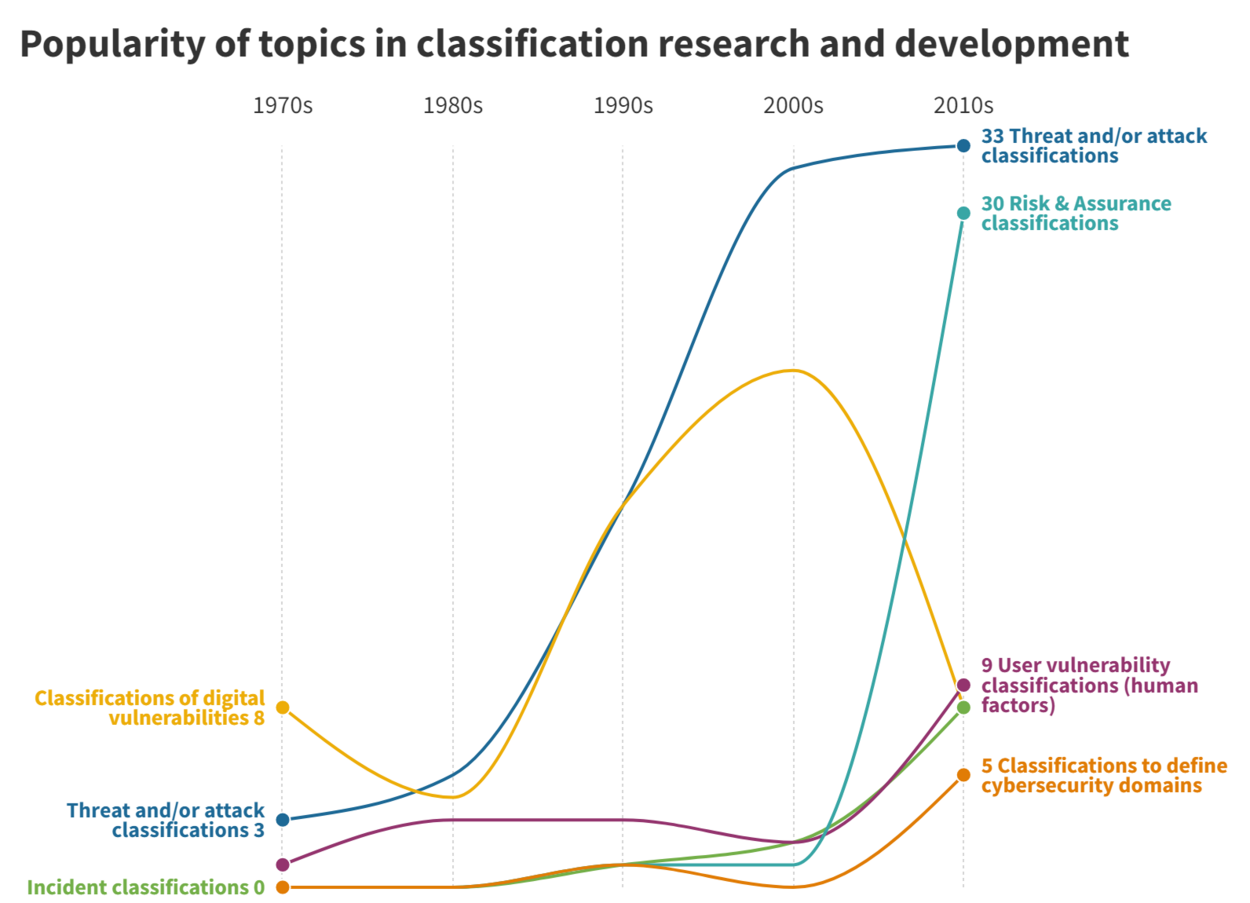
Door de jaren heen zijn er steeds meer specifieke threat & vulnerability taxonomieën opgesteld voor bepaalde besturingssystemen, netwerken, software of voor menselijke fouten. Tegenwoordig beschouwen we cybersecurity vanuit meerdere disciplines. Daardoor zien we door de tijd heen steeds meer gemengde modellen ontstaan waarin dreigingen, kwetsbaarheden en andere factoren worden gecombineerd. Voorbeelden zijn de taxonomieën voor cyberverzekeringen, risico’s of menselijke fouten. Maar ook is er een verbreding van het vakgebied zichtbaar, waarin gedetailleerde classificaties ontstaan voor aanvallen en kwetsbaarheden in operationele processen, zelfrijdende voertuigen, machine learning/artificial intelligence, IoT en OT. Ook taxonomieën om het vakgebied cybersecurity te beschrijven zijn de laatste jaren steeds vaker te zien. Voor een ander gebied neemt de interesse juist af: In de bovenstaande grafiek zie je dat sinds het jaar 2000 steeds minder nieuwe classificaties van kwetsbaarheden worden ontwikkeld. Het is aannemelijk dat dat komt door het ontstaan van internationaal geaccepteerde CVE-conventies in 1999 die steeds meer als standaard zijn aangenomen. We zien nu ook een plateau in het aantal nieuwe publicaties over dreigingen en aanvallen. Dit zou erop kunnen duiden dat een bepaalde taxonomie bovendrijft die als standaard wordt geaccepteerd waardoor de interesse voor nieuwe aanpakken stagneert en de curve zal gaan dalen.
De meeste onderzoekers beginnen hun publicaties met een review van bestaande classificaties en een uitleg waarom die niet passen in hun specifieke situatie. Er is blijkbaar geen one-size-fits-all classificatie, maar de doelen waar onderzoekers aan werken lijken universeel:
- Een kader om de complexe wereld te beschrijven en te begrijpen;
- een manier om kennis te delen en te hergebruiken;
- een structuur om informatie te delen;
- een hulpmiddel om effectiviteit te meten.
Classificatie, typologie, taxonomie, ontologie: allemaal hetzelfde, toch?
Een taxonomie is niet hetzelfde als een ontologie, hoewel ze beide worden gebruikt om fenomenen te beschrijven en classificeren. Een taxonomie is een systeem gebaseerd op hiërarchie (ouder-kind relaties) tussen entiteiten, vaak in een boomstructuur met takken. De entiteiten hebben allemaal maar 1 relatie: die met de ouder of met het kind. Het voordeel van een taxonomie is dat je een structuur hebt die het mogelijk maakt om kenmerken van bijvoorbeeld organisaties, gebeurtenissen of dingen te clusteren, zodat ze gemakkelijk te identificeren, te bestuderen en terug te vinden zijn. In cybersecurity is een taxonomie heel geschikt voor het indelen van soorten incidenten, maatregelen, assets, schade, leveranciers, enzovoorts. Bekende voorbeelden zijn:
- STIX voor dreigingsinformatie
- Cyber Incident taxonomy van ENISA
- De MITRE CWE® taxonomie van kwetsbaarheden
- Het MITRE ATT&CK® framework voor aanvalstechnieken en -tactieken
- Common Platform Enumeration (CPE) om producten en versies te beheren
Een ontologie is ook een classificatiesysteem dat gebruik maakt van een hiërarchie, maar in een ontologie zijn ook andere relaties mogelijk. Als een soort web zijn eigenschappen van concepten beschreven en aan elkaar verbonden. Daar waar een taxonomie zich bezighoudt met het categoriseren van 1 onderwerp, kan een ontologie meerdere entiteiten en meerdere relaties beschrijven. Een ontologie kan dus de relaties weergeven tussen bijvoorbeeld maatregelen en kwetsbaarheden, waarbij een relatie kan worden gelegd tussen meerdere maatregelen en een kwetsbaarheid of tussen een maatregel en meerdere kwetsbaarheden. Ontologieën zijn dus complexer dan taxonomieën en voor cybersecurity nog volop onderwerp van onderzoek en ontwikkeling.
Tenslotte, een typologie zoals de NCSC Threat Actor typology lijkt op een taxonomie. Met het verschil dat een taxonomie tot stand komt op basis van metingen of experimenten (empirisch) en een typologie een conceptuele classificatie is op basis van logisch redeneren.
Ontwikkelingen en de toekomst
Classificaties van cybersecurity fenomenen worden sinds het begin van deze eeuw steeds vaker als ontologie gepresenteerd. Door de toenemende verwevenheid van digitale technologie in de samenleving ontstaan er meer en meer complexe relaties. Niet voor niets wordt in het CSBN 2021 gesproken over het ‘zenuwstelsel’ van de maatschappij. Een taxonomie is nog steeds een goed hulpmiddel om entiteiten binnen een afgebakend onderdeel te organiseren. Een ontologie biedt echter meer inzicht in de complexiteit van relaties tussen fenomenen en kan ook meerdere relaties die tegelijkertijd bestaan in beeld brengen. We zien dit ook terug in publicaties van onderzoek en ontwikkeling op het gebied van classificaties. Op basis van mijn verzameling publicaties zie ik dat men de laatste jaren vooral bezig is met het ontwikkelen van ontologieën.
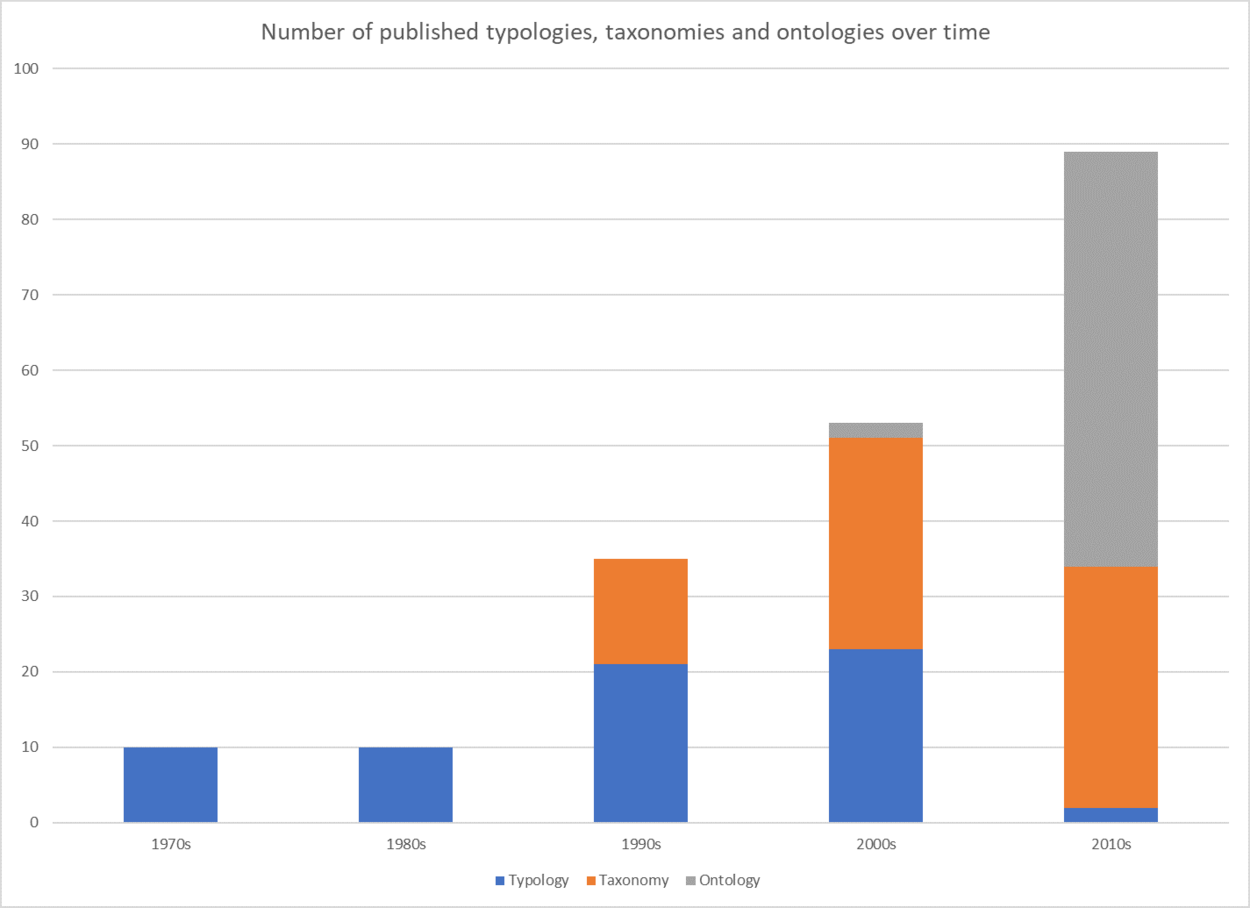
Een uitgebreide ontologie met veel relaties moet worden ondersteund door software om het nog navigeerbaar te houden. Daar staat tegenover dat een ontologie de kapstok kan zijn om diverse databases met elkaar te verbinden. Een voorbeeld is de koppeling van een IT-assetmanagement database met een kwetsbaarheden database. De afzonderlijke databases kunnen zijn opgebouwd met hun eigen terminologie (of taxonomie) maar om te zorgen dat er een relatie kan worden gelegd tussen de databases en er regels kunnen worden opgesteld voor alerts, is een ontologie nodig. Een ontologie kan ook complexere metingen aan. Tien jaar geleden liep ik in mijn PhD-onderzoek naar risicovoorspellingen tegen de beperkingen van een taxonomie aan. Met mijn incidententaxonomie kon ik toen eenvoudige scenario's berekenen. Bijvoorbeeld, in mijn taxonomie werd een incident beschreven als 1 asset met 1 kwetsbaarheid die leidde tot 1 soort schade. De realiteit is natuurlijk dat een incident vaak een samenloop is van omstandigheden waarbij meerdere oorzaken tegelijk betrokken zijn. Een ontologie biedt een betere basis om scenario's voor incidenten en risico's door te rekenen. Uit een studie naar ontwikkelmethoden voor ontologieën blijkt dat veel onderzoekers daarvoor een taal (meestal OWL) en een tool (meestal Protégé) gebruiken. Deze taal en tool bieden ondersteuning om logisch te redeneren wanneer je bijvoorbeeld zoekt naar de juiste classificering van een nieuwe waarneming of gebeurtenis. Deze tools bieden ook ondersteuning voor wiskundige berekeningen. Het NCSC-onderzoek met TNO naar de kwantificering van cybersecurityrisico's verkent het berekenen van risico's met Baysian Belief Networks. Ook ENISA is bezig met het doorontwikkelen van hun incidententaxonomie naar een ontologie. De algemene trend van toenemende samenwerking tussen cybersecurityspecialisten en datascientists zal in de toekomst gaan bijdragen aan het geautomatiseerd berekenen van de complexe relaties tussen data uit verschillende bronnen. Denk daarbij aan onderlinge relaties tussen factoren als dreigingen, aanvallen, kwetsbaarheden, doelwitten, impact, kennis en vaardigheden. Maar ook het leggen van verbanden tussen cybersecuritydata uit verschillende organisaties behoort tot de mogelijkheden. Hiervoor zijn ontologieën en de bijbehorende taal en tools onmisbaar.
Geschreven door: Nicole van Deursen
Meer weblogberichten
Reactie toevoegen
U kunt hier een reactie plaatsen. Ongepaste reacties worden niet geplaatst. Uw reactie mag maximaal 2000 karakters tellen.
Reacties
Er zijn nu geen reacties gepubliceerd.